- Topic1/3
28k Popularity
9k Popularity
15k Popularity
7k Popularity
16k Popularity
- Pin
- 🎉 Gate Square Growth Points Summer Lucky Draw Round 1️⃣ 2️⃣ Is Live!
🎁 Prize pool over $10,000! Win Huawei Mate Tri-fold Phone, F1 Red Bull Racing Car Model, exclusive Gate merch, popular tokens & more!
Try your luck now 👉 https://www.gate.com/activities/pointprize?now_period=12
How to earn Growth Points fast?
1️⃣ Go to [Square], tap the icon next to your avatar to enter [Community Center]
2️⃣ Complete daily tasks like posting, commenting, liking, and chatting to earn points
100% chance to win — prizes guaranteed! Come and draw now!
Event ends: August 9, 16:00 UTC
More details: https://www
- #Gate 2025 Semi-Year Community Gala# voting is in progress! 🔥
Gate Square TOP 40 Creator Leaderboard is out
🙌 Vote to support your favorite creators: www.gate.com/activities/community-vote
Earn Votes by completing daily [Square] tasks. 30 delivered Votes = 1 lucky draw chance!
🎁 Win prizes like iPhone 16 Pro Max, Golden Bull Sculpture, Futures Voucher, and hot tokens.
The more you support, the higher your chances!
Vote to support creators now and win big!
https://www.gate.com/announcements/article/45974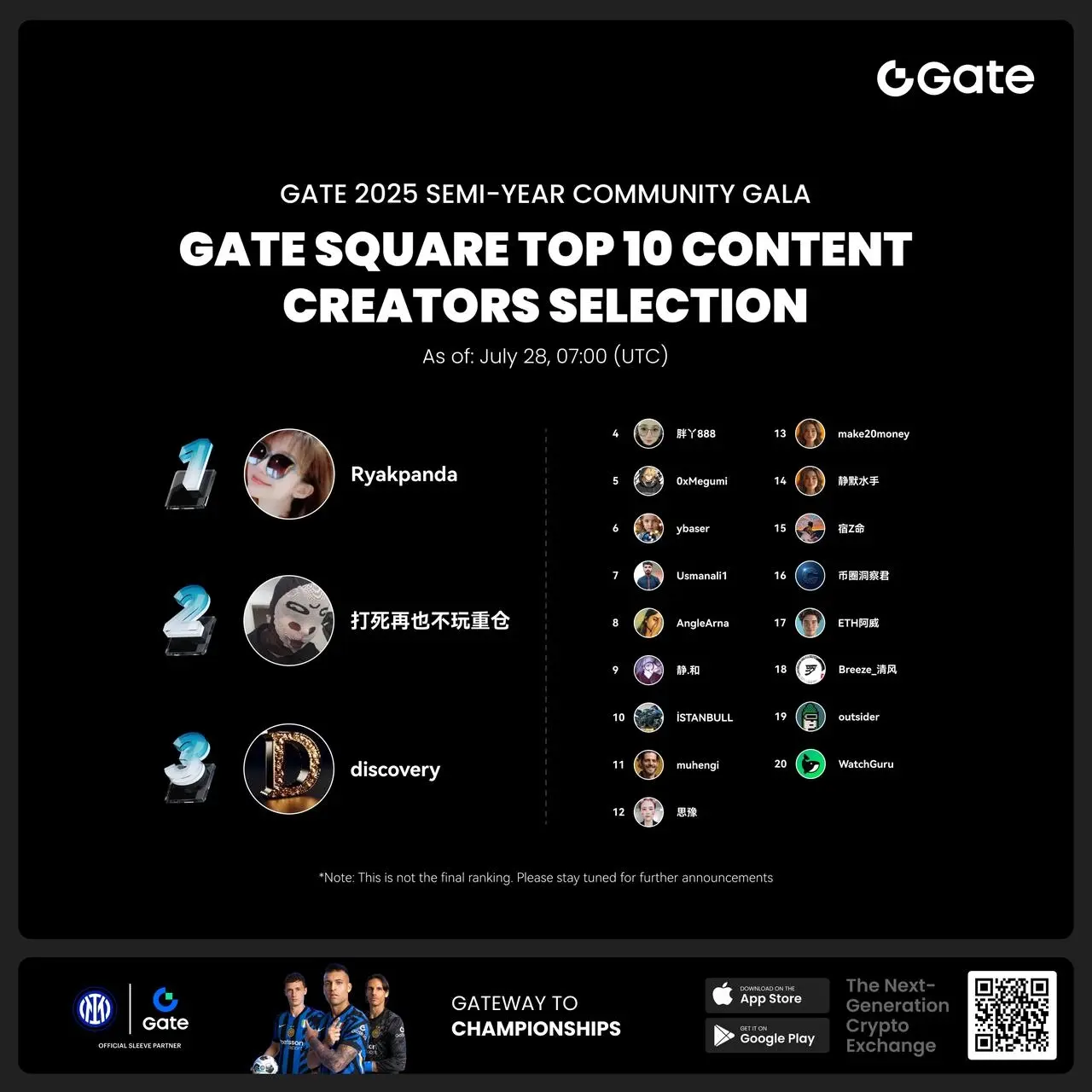
DataFi: Web3 Drives New Trend of AI Data Assetization
Data is Asset: DataFi Opens New Blue Ocean
The world is in an era of competing to build the best foundational models. While computing power and model architecture are important, the real moat is the training data. The biggest news in the AI circle this month is that Meta has demonstrated its strength, with Zuckerberg recruiting talents widely to form a luxury AI team primarily composed of Chinese research talents. The team is led by 28-year-old Alexander Wang, whose company Scale AI is currently valued at $29 billion and provides data services to several competing AI giants, including the U.S. military, OpenAI, Anthropic, and Meta. The core business of Scale AI is to provide a large amount of accurate labeled data.
The Success Path of Scale AI
The reason Scale AI stands out among many unicorns is that it recognized the importance of data in the AI industry early on.
Computing power, models, and data are the three pillars of AI models. If we compare a large model to a person, then the model is the body, computing power is the food, and data is the knowledge/information.
In the rapid development of LLMs, the industry's focus has shifted from models to computing power. Currently, most models have established the transformer as the framework, with occasional innovations such as MoE or MoRe; major players either build their own supercomputing clusters or sign long-term agreements with cloud service providers to address computing power issues. After addressing the basic needs of computing power, the importance of data has gradually become prominent.
Scale AI is committed to building a solid data foundation for AI models, with its business not only focusing on mining existing data but also on long-term data generation. The company forms AI training teams composed of human experts from various fields to provide higher quality data for the training of AI models.
Two Stages of Model Training
Model training is divided into two parts: pre-training and fine-tuning.
Pre-training is similar to the process of human babies learning to speak, requiring the input of a large amount of text, code, and other information crawled from the internet into the AI model, allowing the model to self-learn and master basic communication skills.
Fine-tuning is similar to going to school, where there are usually clear rights and wrongs, answers, and directions. Different "schools" will cultivate different characteristics of "talents." We use some carefully prepared, targeted datasets to enable the model to possess the abilities we desire.
Therefore, we need two types of data:
Massive amounts of data that require minimal processing mainly come from large UGC platform crawling data, public literature databases, private corporate databases, etc.
A professionally curated and meticulously designed dataset requires data cleansing, filtering, labeling, and manual feedback.
These two types of datasets constitute the main body of the AI Data track. It is currently widely believed that as the advantages of computing power gradually disappear, data will become the key for large model manufacturers to maintain competitiveness.
As the capabilities of the model continue to improve, various more refined and specialized training data will become key factors determining the model's abilities. If we compare model training to cultivating a martial arts expert, then high-quality datasets are the best martial arts manuals.
In the long run, AI Data is a long-term track with a snowball effect. As the preliminary work accumulates, data assets will have compounding capability, and their value will grow over time.
Web3 DataFi: The Ideal Soil for AI Data
Compared to traditional data companies, Web3 has a natural advantage in the AI data field, giving rise to the concept of DataFi.
Ideally, the advantages of Web3 DataFi include:
For ordinary users, DataFi is the easiest decentralized AI project to participate in. Users only need to log in to their wallet to participate by completing various tasks, such as providing data, evaluating models, using AI tools for simple creations, and engaging in data trading.
The Potential Projects of Web3 DataFi
Several DataFi projects have already received significant funding, and the following are some representative projects:
These projects currently have generally low barriers, but as user and ecological stickiness accumulates, platform advantages will quickly form. Early projects should focus on incentives and user experience to attract enough users.
At the same time, these platforms also need to pay attention to how to manage manpower, ensure data quality, and avoid the phenomenon of "bad money driving out good" caused by the so-called "毛党". Some projects like Sahara and Sapien have begun to emphasize data quality and strive to establish long-term healthy cooperative relationships with platform users.
In addition, improving transparency is also a challenge faced by current on-chain projects. Many projects still need to accelerate their pace of openness and transparency to promote the long-term healthy development of Web3 DataFi.
The large-scale adoption of DataFi needs to be promoted from two aspects: first, attracting enough individual users to participate in data collection/generation to form a consumer group for the AI economy; second, gaining recognition from mainstream enterprises, as they are the main source of large data orders in the short term.
Conclusion
From a certain perspective, DataFi is about using human intelligence to cultivate machine intelligence over the long term, while ensuring the benefits of human intelligent labor through smart contracts, ultimately enjoying the returns from machine intelligence.
For those filled with uncertainty about the AI era, or who still hold ideals in the blockchain field, following in the footsteps of capital magnates to engage in DataFi is undoubtedly a choice that aligns with the trend.