- Topic1/3
57k Popularity
15k Popularity
47k Popularity
3k Popularity
2k Popularity
- Pin
- #Gate 2025 Semi-Year Community Gala# voting is in progress! 🔥
Gate Square TOP 40 Creator Leaderboard is out
🙌 Vote to support your favorite creators: www.gate.com/activities/community-vote
Earn Votes by completing daily [Square] tasks. 30 delivered Votes = 1 lucky draw chance!
🎁 Win prizes like iPhone 16 Pro Max, Golden Bull Sculpture, Futures Voucher, and hot tokens.
The more you support, the higher your chances!
Vote to support creators now and win big!
https://www.gate.com/announcements/article/45974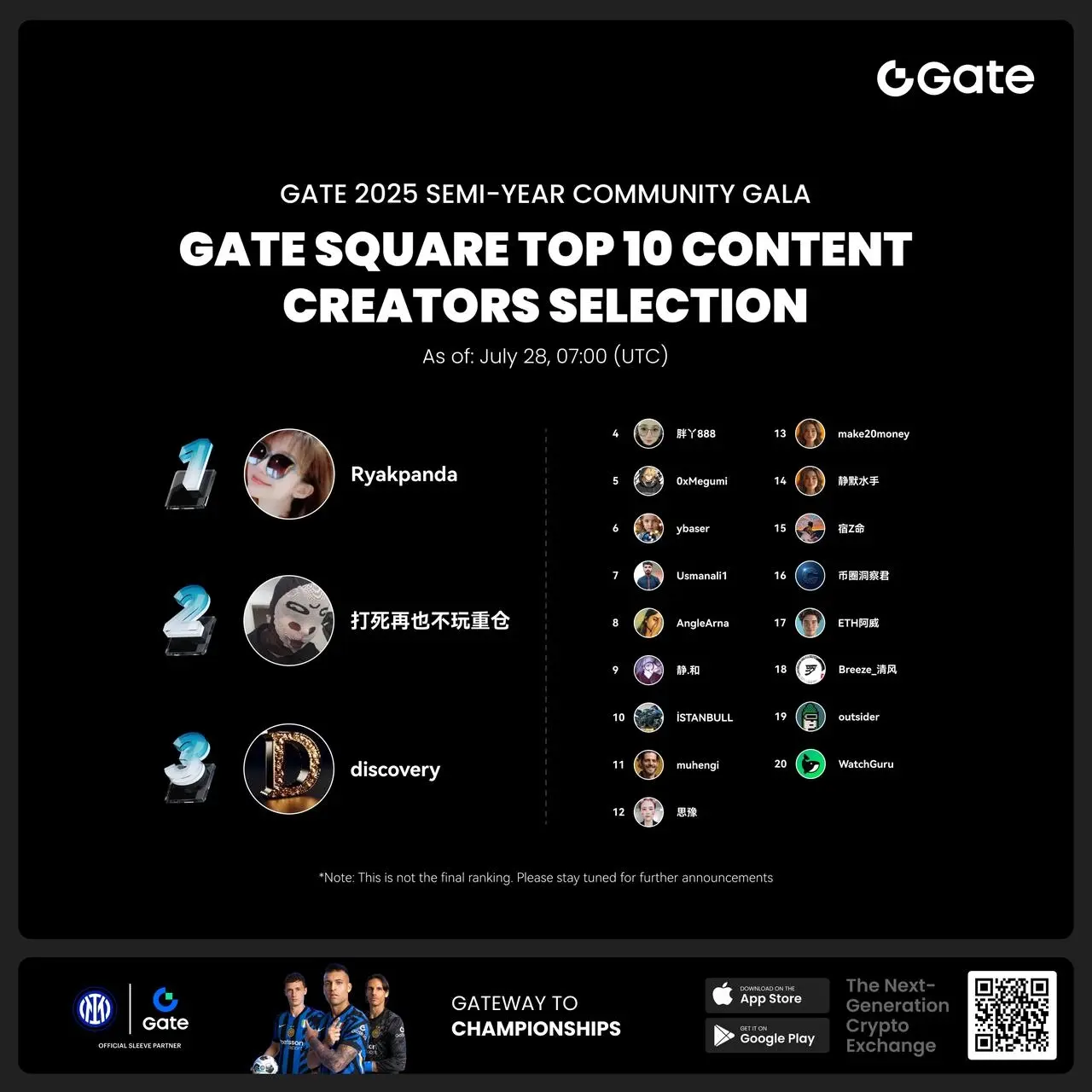
- 🎉 Hey Gate Square friends! Non-stop perks and endless excitement—our hottest posting reward events are ongoing now! The more you post, the more you win. Don’t miss your exclusive goodies! 🚀
1️⃣ #ETH Hits 4800# | Market Analysis & Prediction: Boldly share your ETH predictions to showcase your insights! 10 lucky users will split a 0.1 ETH prize!
Details 👉 https://www.gate.com/post/status/12322612
2️⃣ #Creator Campaign Phase 2# |ZKWASM Topic: Share original content about ZKWASM or its trading activity on X or Gate Square to win a share of 4,000 ZKWASM!
Details 👉 https://www.gate.com/post/st - 📢 Gate Square #Creator Campaign Phase 2# is officially live!
Join the ZKWASM event series, share your insights, and win a share of 4,000 $ZKWASM!
As a pioneer in zk-based public chains, ZKWASM is now being prominently promoted on the Gate platform!
Three major campaigns are launching simultaneously: Launchpool subscription, CandyDrop airdrop, and Alpha exclusive trading — don’t miss out!
🎨 Campaign 1: Post on Gate Square and win content rewards
📅 Time: July 25, 22:00 – July 29, 22:00 (UTC+8)
📌 How to participate:
Post original content (at least 100 words) on Gate Square related to
The Integration of AI and Crypto Assets: From Basics to Future Development
AI x Crypto: From Zero to Peak
The recent developments in the AI industry are viewed by some as the Fourth Industrial Revolution. The emergence of large models has significantly improved efficiency across various sectors, estimated to have increased work efficiency in the United States by about 20%. At the same time, the generalization capabilities brought by large models are considered a new paradigm in software design; whereas past software design relied on precise code, the current approach embeds more generalized large model frameworks into software, enabling these applications to exhibit better performance and support a wider range of input and output modalities. Deep learning technology has brought about a fourth boom in the AI industry, and this trend has also impacted the cryptocurrency sector.
This report will provide a detailed exploration of the development history of the AI industry, the classification of technologies, and the impact of deep learning technology on the industry. It will then conduct an in-depth analysis of the current status and trends of the upstream and downstream of the industrial chain, including GPU, cloud computing, data sources, and edge devices in deep learning. Finally, it will fundamentally explore the relationship between cryptocurrency and the AI industry, sorting out the landscape of the AI industrial chain related to cryptocurrency.
The Development History of the AI Industry
The AI industry started in the 1950s. To realize the vision of artificial intelligence, academia and industry have developed various schools of thought for achieving artificial intelligence in different eras and disciplines.
Modern artificial intelligence technology mainly uses the term "machine learning." The concept of this technology is to allow machines to iteratively improve system performance in tasks based on data. The main steps are to feed data into algorithms, train models using this data, test and deploy the models, and use the models to complete automated prediction tasks.
Currently, there are three main schools of thought in machine learning: connectionism, symbolism, and behaviorism, which respectively mimic the human nervous system, thinking, and behavior.
Currently, connectionism represented by neural networks holds the upper hand ( also known as deep learning ). The main reason is that this architecture has an input layer, an output layer, but multiple hidden layers. Once the number of layers and neurons ( parameters ) becomes sufficiently large, there are enough opportunities to fit complex general tasks. Through data input, the parameters of the neurons can be continuously adjusted, and after going through multiple data, the neuron will reach an optimal state ( parameters ), which is known as "great effort leads to miracles," and this is also the origin of the term "deep"—sufficient layers and neurons.
For example, it can be simply understood as constructing a function where when we input X=2, Y=3; and when X=3, Y=5. If we want this function to handle all X values, we need to keep adding the degree of this function and its parameters. For instance, I can construct a function that satisfies this condition as Y = 2X - 1. However, if there is a data point where X=2 and Y=11, we need to reconstruct a function suitable for these three data points. Using a GPU for brute force cracking, we find Y = X^2 - 3X + 5, which seems more appropriate. However, it doesn’t need to match the data points completely; it just needs to maintain balance and provide output that is roughly similar. In this context, X^2, X, and X0 represent different neurons, while 1, -3, and 5 are their parameters.
At this point, if we input a large amount of data into the neural network, we can increase the number of neurons and iterate the parameters to fit the new data. This way, we can fit all the data.
Based on neural network deep learning technology, there have been multiple iterations and evolutions, such as the earliest neural networks, feedforward neural networks, RNNs, CNNs, and GANs, ultimately evolving into modern large models like GPT that utilize Transformer technology. The Transformer technology is just one evolutionary direction of neural networks, adding a converter ( Transformer ) to encode data from all modalities ( such as audio, video, images, etc. ) into corresponding numerical representations. This data is then input into the neural network, enabling the neural network to fit any type of data, thereby achieving multimodality.
The development of AI has gone through three technological waves. The first wave occurred in the 1960s, a decade after the proposal of AI technology. This wave was triggered by the development of symbolic technology, which addressed issues of general natural language processing and human-computer dialogue. During the same period, expert systems were born, such as the DENRAL expert system, which was completed under the supervision of Stanford University and NASA in the United States. This system possesses a very strong knowledge of chemistry and infers answers similar to those of a chemistry expert through questioning. This chemistry expert system can be seen as a combination of a chemistry knowledge base and an inference system.
After expert systems, in the 1990s, Israeli-American scientist and philosopher Judea Pearl ( proposed Bayesian networks, which are also known as belief networks. During the same period, Brooks proposed behavior-based robotics, marking the birth of behaviorism.
In 1997, IBM's Deep Blue defeated the chess champion Garry Kasparov 3.5:2.5, and this victory was seen as a milestone for artificial intelligence, marking the peak of the second wave of AI technology development.
The third wave of AI technology occurred in 2006. The three giants of deep learning, Yann LeCun, Geoffrey Hinton, and Yoshua Bengio, proposed the concept of deep learning, an algorithm based on artificial neural networks for representation learning of data. Subsequently, deep learning algorithms evolved gradually, from RNN and GAN to Transformer and Stable Diffusion. These two algorithms together shaped this third technological wave, marking the peak of connectionism.
Many iconic events have gradually emerged alongside the exploration and evolution of deep learning technology, including:
In 2011, IBM's Watson) won the championship in the quiz show Jeopardy( by defeating humans.
In 2014, Goodfellow proposed GAN), Generative Adversarial Network(, which learns by allowing two neural networks to compete against each other, capable of generating photorealistic images. At the same time, Goodfellow also wrote a book titled "Deep Learning," known as the "flower book," which is one of the important introductory books in the field of deep learning.
In 2015, Hinton and others proposed deep learning algorithms in the journal "Nature", and the introduction of this deep learning method immediately caused a huge response in both academia and industry.
In 2015, OpenAI was founded, with Musk, Y Combinator president Altman, angel investor Peter Thiel ) and others announcing a joint investment of $1 billion.
In 2016, AlphaGo, based on deep learning technology, competed against the world champion and professional 9-dan Go player Lee Sedol in a human-computer Go match, winning with a total score of 4 to 1.
In 2017, the Hong Kong-based Hanson Robotics company ( developed the humanoid robot Sophia, which is known as the first robot in history to be granted citizenship, possessing a rich array of facial expressions and the ability to understand human language.
In 2017, Google, with its rich talent and technological reserves in the field of artificial intelligence, published the paper "Attention is all you need" proposing the Transformer algorithm, and large-scale language models began to emerge.
In 2018, OpenAI released the GPT) Generative Pre-trained Transformer( built on the Transformer algorithm, which was one of the largest language models at the time.
In 2018, Google's Deepmind team released AlphaGo based on deep learning, capable of predicting protein structures, which is regarded as a significant milestone in the field of artificial intelligence.
In 2019, OpenAI released GPT-2, which has 1.5 billion parameters.
In 2020, OpenAI developed GPT-3, which has 175 billion parameters, 100 times more than the previous version GPT-2. This model was trained on 570GB of text and can achieve state-of-the-art performance in various NLP) natural language processing( tasks) such as question answering, translation, and writing articles(.
In 2021, OpenAI released GPT-4, which has 1.76 trillion parameters, ten times that of GPT-3.
The ChatGPT application based on the GPT-4 model was launched in January 2023, and by March, ChatGPT reached one hundred million users, becoming the fastest application in history to reach one hundred million users.
In 2024, OpenAI will launch GPT-4 omni.
![Newbie Science Popularization丨AI x Crypto: From Zero to Peak])https://img-cdn.gateio.im/webp-social/moments-0c9bdea33a39a2c07d1f06760ed7e804.webp(
Deep Learning Industrial Chain
The current large language models are all based on deep learning methods utilizing neural networks. Led by GPT, large models have created a wave of artificial intelligence enthusiasm, with a large number of players entering this field. We have also noticed a significant surge in market demand for data and computing power. Therefore, in this part of the report, we mainly explore the industrial chain of deep learning algorithms. In the AI industry dominated by deep learning algorithms, we examine how the upstream and downstream are composed, as well as the current state of the upstream and downstream, their supply and demand relationships, and future developments.
First, we need to clarify that when training large models based on GPT and other LLMs using Transformer technology, there are a total of three steps.
Before training, as it is based on Transformer, the converter needs to convert text input into numerical values. This process is called "Tokenization"; thereafter, these numerical values are referred to as Tokens. Under general empirical rules, an English word or character can be roughly viewed as one Token, while each Chinese character can be roughly viewed as two Tokens. This is also the basic unit used for GPT pricing.
Step one, pre-training. By providing the input layer with enough data pairs, similar to the examples given in the first part of the report )X,Y(, to find the optimal parameters for each neuron under the model. This requires a large amount of data and is also the most computationally intensive process, as it involves repeatedly iterating the neurons to try various parameters. After a batch of data pairs is trained, the same batch of data is generally used for secondary training to iterate the parameters.
Step two, fine-tuning. Fine-tuning involves providing a smaller batch of high-quality data for training, which will improve the quality of the model's output. This is because pre-training requires a large amount of data, but much of this data may contain errors or be of low quality. The fine-tuning step can enhance the quality of the model through high-quality data.
Step three, reinforcement learning. First, a brand new model will be established, which we call the "reward model". The purpose of this model is very simple: to rank the output results. Therefore, implementing this model will be relatively straightforward, as the business scenario is quite vertical. After that, this model will be used to determine whether the output of our large model is of high quality, allowing us to use a reward model to automatically iterate the parameters of the large model. ) However, sometimes human involvement is also needed to assess the output quality of the model (.
In short, during the training process of large models, pre-training has very high requirements for the amount of data, and the GPU computing power required is also the highest. Fine-tuning requires higher quality data to improve parameters, while reinforcement learning can iteratively adjust parameters through a reward model to produce higher quality results.
During the training process, the more parameters there are, the higher the ceiling of generalization ability. For example, in the case of the function Y = aX + b, there are actually two neurons, X and X0. Therefore, the way parameters change limits the data that can be fitted, because it is essentially still a straight line. If there are more neurons, then more parameters can be iterated, allowing for more data to be fitted. This is why large models work wonders, and it is also why they are commonly referred to as large models, which essentially consist of a massive number of neurons and parameters, as well as a vast amount of data, all of which require substantial computational power.
Therefore, the performance of large models is primarily determined by three aspects: the number of parameters, the amount and quality of data, and computing power. These three factors collectively influence the quality of the results and the generalization ability of the large models. Let's assume the number of parameters is p, and the amount of data is n) calculated in terms of Token count(. We can then estimate the required computing power using general rules of thumb, which allows us to roughly estimate the computing power we need to purchase and the training time.
Computing power is generally measured in Flops, which represents a single floating-point operation. Floating-point operations refer to the general term for arithmetic operations on non-integer values, such as 2.5 + 3.557. Floating-point indicates the capability to include decimal points, while FP16 represents support.