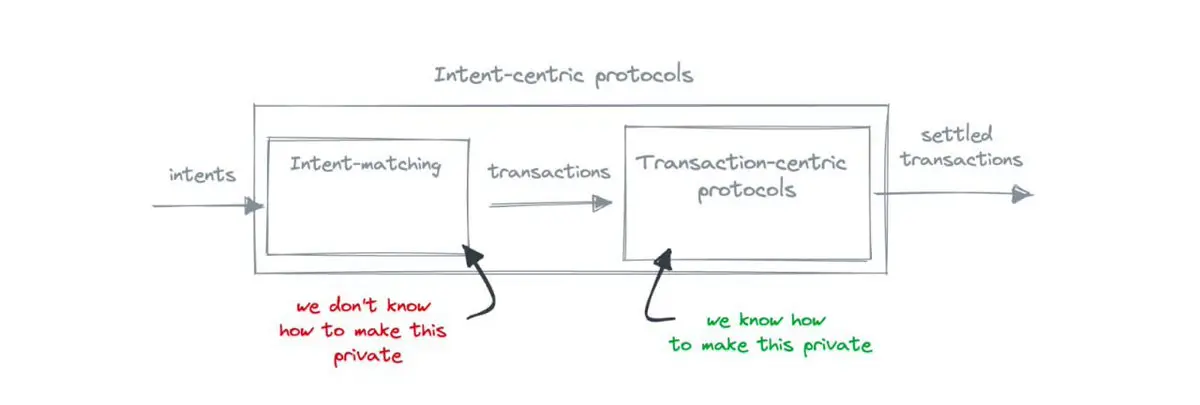
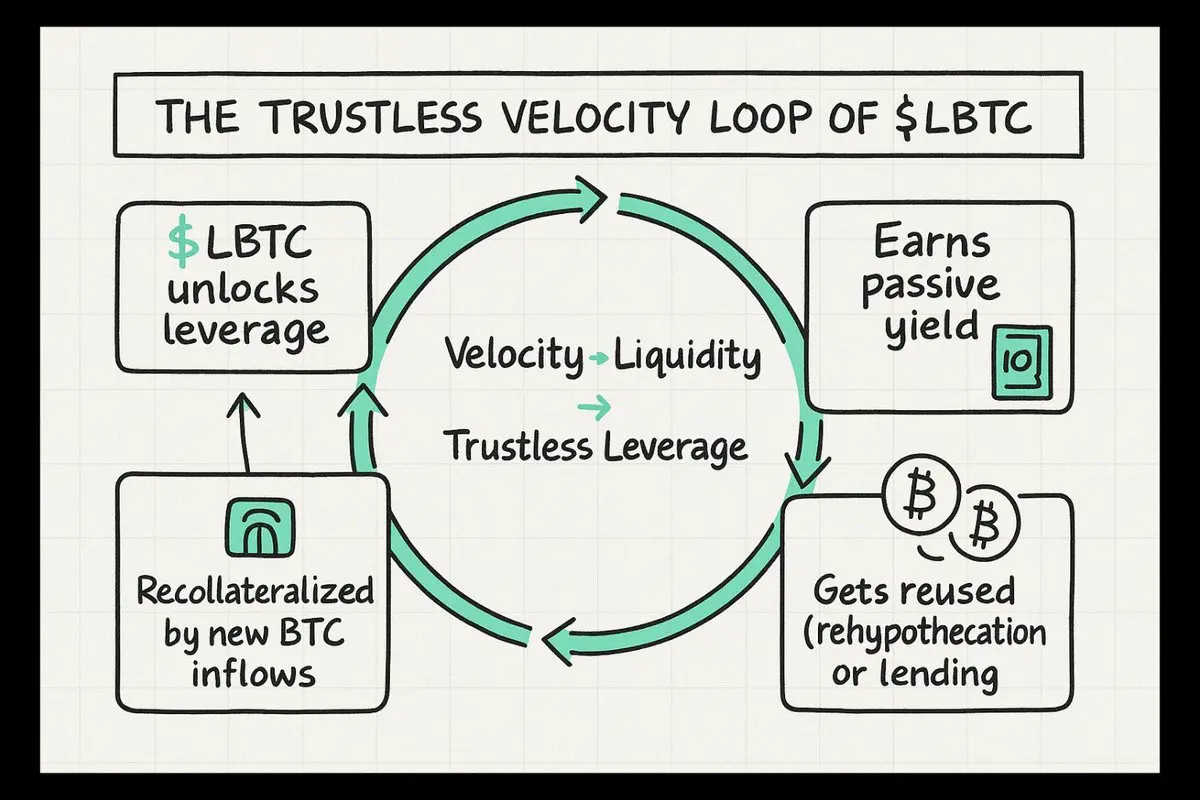
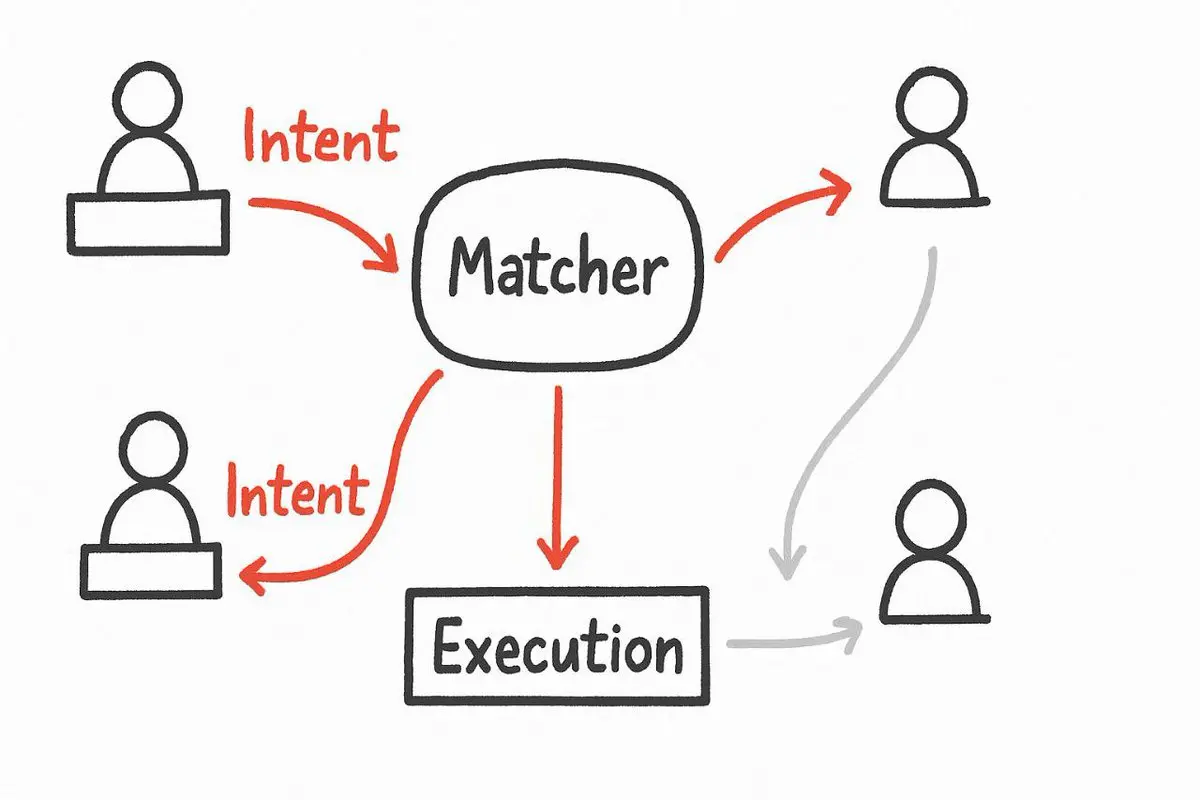
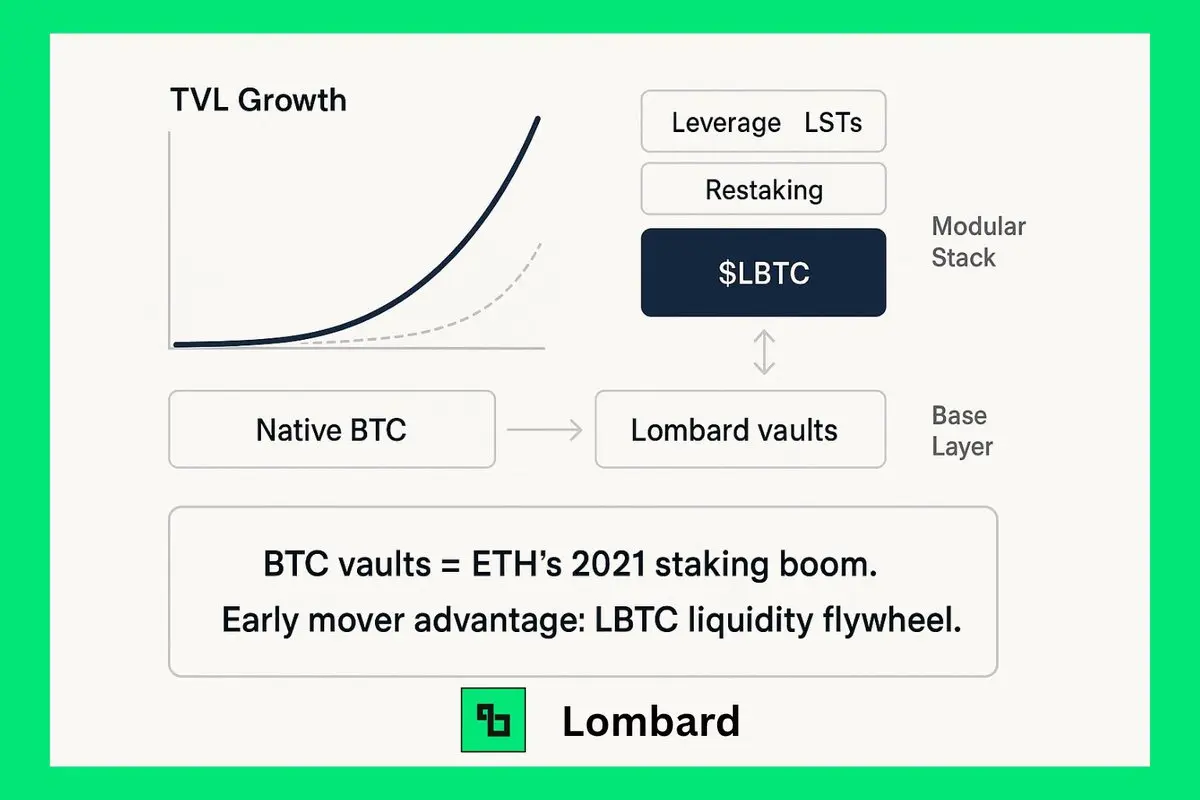
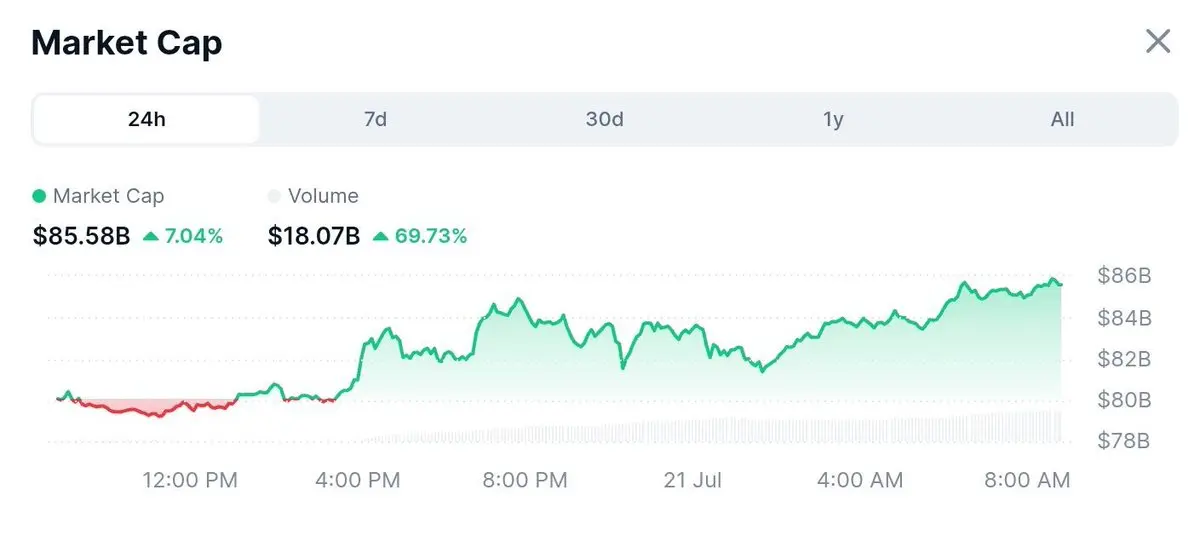
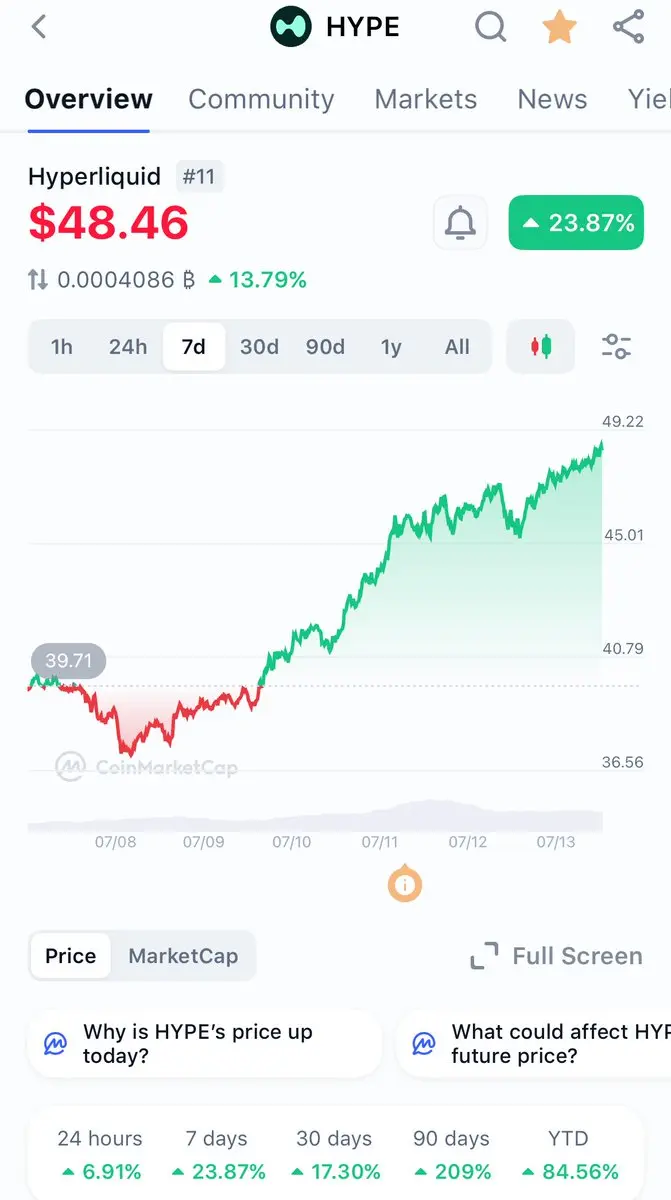
Kingbest
今日のデフォルトのAIはより大きな基盤モデルを持っていますが、それは遅く、高価で、専門化が難しいです。
それを見ていると、$10Mのモノリスで知性をスケールすることはできません。
モジュラリティでそれを拡張します。
イーサリアムは速くならなかった。状態を分割することでモジュラー化した:
- ロールアップ
- シャード
- DAレイヤー
@Mira_Networkは、LoRAを通じてAIに同じ原理を適用しています
LoRA = インテリジェンスシャード
各LoRAは小さな専門モジュールであり、専門知識の断片です。
- DeFiホワイトペーパー用の1つのLoRA
- DAOの提案のための1つ
- 1つは多言語要約用です
一般的な専門家は必要ありません。
あなたは専門家を編成します。
どのように動作するか
1. ModelFactory: 誰でもLoRAモジュールをトレーニングできます
2. OpenLoRA レジストリ: 各 LoRA はオンチェーンであり、コンポーザブルで、トレース可能です。
3. モデルルーター: クエリを正しいLoRAスワームにルーティングします
4. ミラノード: マルチモデルコンセンサスを通じて出力を検証する
これは、Ethereumが認知のためにシャーディングするのと同じです。
なぜこのアプローチが勝つのか
- フルモデルを再訓練するよりも安価
- より速い
原文表示それを見ていると、$10Mのモノリスで知性をスケールすることはできません。
モジュラリティでそれを拡張します。
イーサリアムは速くならなかった。状態を分割することでモジュラー化した:
- ロールアップ
- シャード
- DAレイヤー
@Mira_Networkは、LoRAを通じてAIに同じ原理を適用しています
LoRA = インテリジェンスシャード
各LoRAは小さな専門モジュールであり、専門知識の断片です。
- DeFiホワイトペーパー用の1つのLoRA
- DAOの提案のための1つ
- 1つは多言語要約用です
一般的な専門家は必要ありません。
あなたは専門家を編成します。
どのように動作するか
1. ModelFactory: 誰でもLoRAモジュールをトレーニングできます
2. OpenLoRA レジストリ: 各 LoRA はオンチェーンであり、コンポーザブルで、トレース可能です。
3. モデルルーター: クエリを正しいLoRAスワームにルーティングします
4. ミラノード: マルチモデルコンセンサスを通じて出力を検証する
これは、Ethereumが認知のためにシャーディングするのと同じです。
なぜこのアプローチが勝つのか
- フルモデルを再訓練するよりも安価
- より速い